Workflow to Incorporate MATLAB Map and Reduce Functions into a Hadoop Job
![]()
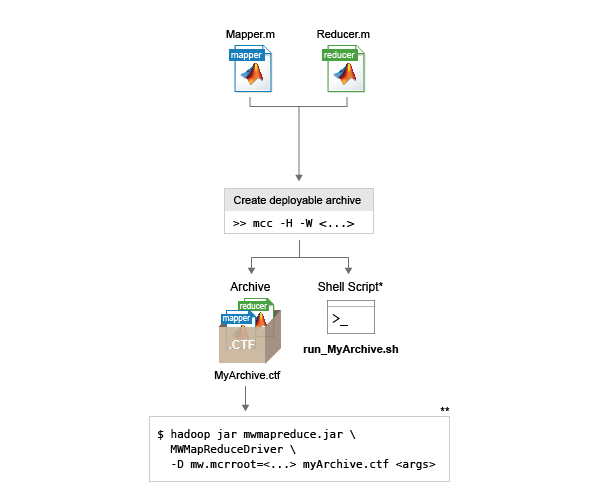
Write mapper and reducer functions in MATLAB®.
Create a MAT-file that contains a datastore that describes the structure of the data and the names of the variables to analyze. The datastore in the MAT-file can be created from a test data set that is representative of the actual data set.
Create a text file that contains Hadoop® settings such as the name of the mapper, reducer, and the type of data being analyzed. This file is automatically created if you are using the Hadoop Compiler app.
Use the Hadoop Compiler app or the
mcccommand to package the components into a deployable archive. Both options generate a deployable archive (.ctf file) that can be incorporated into a Hadoop mapreduce job.Incorporate the deployable archive into a Hadoop mapreduce job using the
hadoopcommand and syntax.Execution Signature

Key
Letter Description A Hadoop command B JAR option C The standard name of the JAR file. All applications have the same JAR: mwmapreduce.jar.The path to the JAR is also fixed relative to the MATLAB Runtime location.D The standard name of the driver. All applications have the same driver name: MWMapReduceDriverE A generic option specifying the MATLAB Runtime location as a key-value pair. F Deployable archive ( .ctffile) generated by the Hadoop Compiler app ormccis passed as a payload argument to the job.G Location of input files on HDFS™. H Location on HDFS where output can be written.
To simplify the inclusion of the deployable archive (.ctf file)
into a Hadoop mapreduce job, both the Hadoop Compiler app and the
mcc command generate a shell script alongside the
deployable archive. The shell script has the following naming convention:
run_<deployableArchiveName>.sh
To run the deployable archive using the shell script, use the following syntax:
