Accessing Advanced CUDA Features Using MEX
This example demonstrates how advanced features of the GPU can be accessed using MEX files. It builds on the example Stencil Operations on a GPU. The previous example uses Conway's "Game of Life" to demonstrate how stencil operations can be performed using MATLAB® code that runs on a GPU. The present example demonstrates how you can further improve the performance of stencil operations using two advanced features of the GPU: shared memory and texture memory. You do this by writing your own CUDA code in a MEX file and calling the MEX file from MATLAB. You can find an introduction to the use of the GPU in MEX files in the documentation.documentation.
As defined in the previous example, in a "stencil operation", each element of the output array depends on a small region of the input array. Examples include finite differences, convolution, median filtering, and finite-element methods. If we assume that the stencil operation is a key part of our work-flow, we could take the time to convert it to a hand-written CUDA kernel in the hope of getting maximum benefit from the GPU. This example uses Conway's "Game of Life" as our stencil operation, and moves the calculation into a MEX file.
The "Game of Life" follows a few simple rules:
Cells are arranged in a 2D grid
At each step, the fate of each cell is determined by the vitality of its eight nearest neighbors
Any cell with exactly three live neighbors comes to life at the next step
A live cell with exactly two live neighbors remains alive at the next step
All other cells (including those with more than three neighbors) die at the next step or remain empty
The "stencil" in this case is therefore the 3x3 region around each element. For more details, view the code for paralleldemo_gpu_stencilview the code for paralleldemo_gpu_stencil.
This example is a function to allow us to use sub-functions:
function paralleldemo_gpu_mexstencil()
Generate a random initial population
An initial population of cells is created on a 2D grid with approximately 25% of the locations alive.
gridSize = 500;
numGenerations = 100;
initialGrid = (rand(gridSize,gridSize) > .75);
hold off
imagesc(initialGrid);
colormap([1 1 1;0 0.5 0]);
title('Initial Grid');
Create a baseline GPU version in MATLAB
To get a performance baseline, we start with the initial implementation described in Experiments in MATLAB. This version can run on the GPU by simply making sure the initial population is on the GPU using gpuArraygpuArray.
function X = updateGrid(X, N) p = [1 1:N-1]; q = [2:N N]; % Count how many of the eight neighbors are alive. neighbors = X(:,p) + X(:,q) + X(p,:) + X(q,:) + ... X(p,p) + X(q,q) + X(p,q) + X(q,p); % A live cell with two live neighbors, or any cell with % three live neighbors, is alive at the next step. X = (X & (neighbors == 2)) | (neighbors == 3); end currentGrid = gpuArray(initialGrid); % Loop through each generation updating the grid and displaying it for generation = 1:numGenerations currentGrid = updateGrid(currentGrid, gridSize); imagesc(currentGrid); title(num2str(generation)); drawnow; end
Now re-run the game and measure how long it takes for each generation.
% This function defines the outer loop that calls each generation, without % doing the display. function grid=callUpdateGrid(grid, gridSize, N) for gen = 1:N grid = updateGrid(grid, gridSize); end end gpuInitialGrid = gpuArray(initialGrid); % Retain this result to verify the correctness of each version below. expectedResult = callUpdateGrid(gpuInitialGrid, gridSize, numGenerations); gpuBuiltinsTime = gputimeit(@() callUpdateGrid(gpuInitialGrid, ... gridSize, numGenerations)); fprintf('Average time on the GPU: %2.3fms per generation \n', ... 1000*gpuBuiltinsTime/numGenerations);
Average time on the GPU: 1.528ms per generation
Create a MEX version that uses shared memory
When writing a CUDA kernel version of the stencil operation, we have to split the input data into blocks on which each thread block can operate. Each thread in the block will be reading data that is also needed by other threads in the block. One way to minimize the number of read operations is to copy the required input data into shared memory before processing. This copy must include some neighboring elements to allow correct calculation of the block edges. For the Game of Life, where our stencil is just a 3x3 square of elements, we need a one element boundary. For example, for a 9x9 grid processed using 3x3 blocks, the fifth block would operate on the highlighted region, where the yellow elements are the "halo" it must also read.
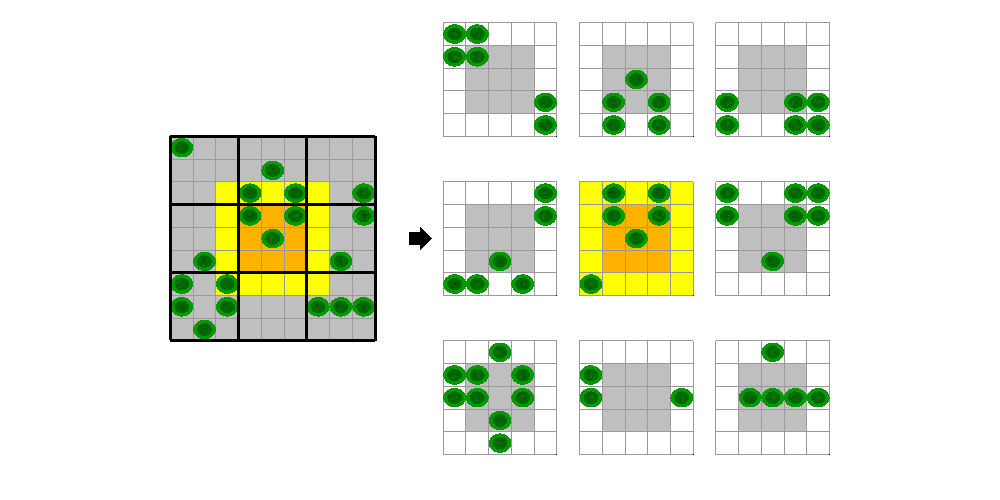
We have put the CUDA code that illustrates this approach into the file pctdemo_life_cuda_shmem.cupctdemo_life_cuda_shmem.cu. The CUDA device function in this file operates as follows:
All threads copy the relevant part of the input grid into shared memory, including the halo.
The threads synchronize with one another to ensure shared memory is ready.
Threads that fit in the output grid perform the Game of Life calculation.
The host code in this file invokes the CUDA device function once for each generation, using the CUDA runtime API. It uses two different writable buffers for the input and output. At every iteration, the MEX-file swaps the input and output pointers so that no copying is required.
In order to call the function from MATLAB, we need a MEX gateway that unwraps the input arrays from MATLAB, builds a workspace on the GPU, and returns the output. The MEX gateway function can be found in the file pctdemo_life_mex_shmem.cpppctdemo_life_mex_shmem.cpp.
Before we can call the MEX-file, we must compile it using mexcuda, which requires installing the nvcc compiler. You can compile these two files into a single MEX function using a command like
mexcuda -output pctdemo_life_mex_shmem ...
pctdemo_life_cuda_shmem.cu pctdemo_life_mex_shmem.cppwhich will produce a MEX file named pctdemo_life_mex_shmem.
% Calculate the output value using the MEX file with shared memory. The % initial input value is copied to the GPU inside the MEX file. grid = pctdemo_life_mex_shmem(initialGrid, numGenerations); gpuMexTime = gputimeit(@()pctdemo_life_mex_shmem(initialGrid, ... numGenerations)); % Print out the average computation time and check the result is unchanged. fprintf('Average time of %2.3fms per generation (%1.1fx faster).\n', ... 1000*gpuMexTime/numGenerations, gpuBuiltinsTime/gpuMexTime); assert(isequal(grid, expectedResult));
Average time of 0.055ms per generation (27.7x faster).
Create a MEX version that uses texture memory
A second way to deal with the issue of repeated read operations is to use the GPU's texture memory. Texture accesses are cached in a way that attempts to provide good performance when several threads access overlapping 2-D data. This is exactly the access pattern that we have in a stencil operation.
There are two CUDA APIs that can be used to read texture memory. We choose to use the CUDA texture reference API, which is supported on all CUDA devices. The maximum number of elements that can be in an array bound to a texture is
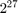 , so the texture approach will not work if the input has more elements.
, so the texture approach will not work if the input has more elements.
The CUDA code that illustrates this approach is in pctdemo_life_cuda_texture.cupctdemo_life_cuda_texture.cu. As in the previous version, this file contains both host code and device code. Three features of this file enable the use of texture memory in the device function.
The texture variable is declared at the top of the MEX-file.
The CUDA device function fetches the input from the texture reference.
The MEX-file binds the texture reference to the input buffer.
In this file, the CUDA device function is simpler than before. It only needs to perform the Game of Life calculations. There is no need to copy into shared memory or to synchronize the threads.
As in the shared-memory version, the host code invokes the CUDA device function once for each generation, using the CUDA runtime API. It again uses two writable buffers for the input and output and swaps their pointers at every iteration. Before each call to the device function, it binds the texture reference to the appropriate buffer. After the device function has executed, it unbinds the texture reference.
There is a MEX gateway file for this version, pctdemo_life_mex_texture.cpppctdemo_life_mex_texture.cpp that takes care of the input and output arrays and of workspace allocation. These files can be built into a single MEX file using a command like the following.
mexcuda -output pctdemo_life_mex_texture ...
pctdemo_life_cuda_texture.cu pctdemo_life_mex_texture.cpp% Calculate the output value using the MEX file with textures. grid = pctdemo_life_mex_texture(initialGrid, numGenerations); gpuTexMexTime = gputimeit(@()pctdemo_life_mex_texture(initialGrid, ... numGenerations)); % Print out the average computation time and check the result is unchanged. fprintf('Average time of %2.3fms per generation (%1.1fx faster).\n', ... 1000*gpuTexMexTime/numGenerations, gpuBuiltinsTime/gpuTexMexTime); assert(isequal(grid, expectedResult));
Average time of 0.025ms per generation (61.5x faster).
Conclusions
In this example, we have illustrated two different ways to deal with copying inputs for stencil operations: explicitly copy blocks into shared memory, or take advantage of the GPU's texture cache. The best approach will depend on the size of the stencil, the size of the overlap region, and the hardware generation of your GPU. The important point is that you can use each of these approaches in conjunction with your MATLAB code to optimize your application.
fprintf('First version using gpuArray: %2.3fms per generation.\n', ... 1000*gpuBuiltinsTime/numGenerations); fprintf(['MEX with shared memory: %2.3fms per generation ',... '(%1.1fx faster).\n'], 1000*gpuMexTime/numGenerations, ... gpuBuiltinsTime/gpuMexTime); fprintf(['MEX with texture memory: %2.3fms per generation '... '(%1.1fx faster).\n']', 1000*gpuTexMexTime/numGenerations, ... gpuBuiltinsTime/gpuTexMexTime);
First version using gpuArray: 1.528ms per generation. MEX with shared memory: 0.055ms per generation (27.7x faster). MEX with texture memory: 0.025ms per generation (61.5x faster).
end