Program Independent Jobs for a Generic Scheduler
Overview
Parallel Computing Toolbox™ software provides a generic interface that lets you interact with third-party schedulers, or use your own scripts for distributing tasks to other nodes on the cluster for evaluation. For this purpose, you also need MATLAB® Distributed Computing Server™ running on your cluster.
Because each job in your application is comprised of several tasks, the purpose of your scheduler is to allocate a cluster node for the evaluation of each task, or to distribute each task to a cluster node. The scheduler starts remote MATLAB worker sessions on the cluster nodes to evaluate individual tasks of the job. To evaluate its task, a MATLAB worker session needs access to certain information, such as where to find the job and task data. The generic scheduler interface provides a means of getting tasks from your Parallel Computing Toolbox client session to your scheduler and thereby to your cluster nodes.
To evaluate a task, a worker requires five parameters that you must pass from the client to the worker. The parameters can be passed any way you want to transfer them, but because a particular one must be an environment variable, the examples in this section pass all parameters as environment variables.
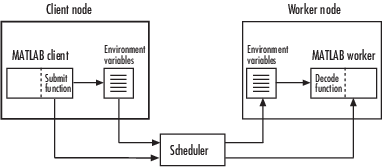
The workflow for programming independent jobs for a generic scheduler is as follows.
Write a MATLAB client submit function.
Write a MATLAB worker decode function.
Create a scheduler object, a job and a task.
Submit a job to the queue and retrieve the results.
Examine details of the workflow in the following section.
Note
Whereas the MJS keeps MATLAB workers running between tasks, a third-party scheduler runs MATLAB workers for only as long as it takes each worker to evaluate its one task.
MATLAB Client Submit Function
When you submit an independent job to a cluster, the independentSubmitFcn.m function
executes in the MATLAB client session. You must set the IntegrationScriptsLocation property
to specify the folder containing the submit functions for this cluster.
See Example — Program and Run a Job in the Client.
The submit function is called with three arguments, in the following
order: cluster, job, and props.
The declaration line of the function must be:
function independentSubmitFcn(cluster, job, props)You can use the AdditionalProperties property
to pass additional information into the submit function. For example:
c.AdditionalProperties.TimeLimit = 300;
c.AdditionalProperties.TestLocation = 'Plant30';
You can then write a submit function which checks for the existence of these properties and behaves accordingly:
if isprop(cluster.AdditionalProperties, 'TimeLimit') time_limit = cluster. AdditionalProperties.TimeLimit; % Add code to appropriately handle this property for your particular scheduler end
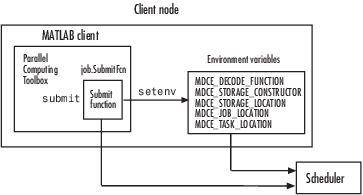
This submit function has three main purposes:
To identify the decode function that MATLAB workers run when they start
To make information about job and task data locations available to the workers via their decode function
To instruct your scheduler how to start a MATLAB worker on the cluster for each task of your job
Identify the Decode Function
The client’s submit function and the worker’s
decode function work together as a pair. Therefore, the submit function
must identify its corresponding decode function. The submit function
does this by setting the environment variable MDCE_DECODE_FUNCTION.
The value of this variable is a character vector identifying the name
of the decode function on the path of the MATLAB worker.
Neither the decode function itself nor its name can be passed to the
worker in a job or task property; the file must already exist before
the worker starts. For more information on the decode function, see MATLAB Worker Decode Function.
Standard decode functions for independent and communicating jobs are
provided with the product. If your submit functions make use of the
definitions in these decode functions, you do not have to provide
your own decode functions. For example, to use the standard decode
function for independent jobs, in your submit function set MDCE_DECODE_FUNCTION to 'parallel.cluster.generic.independentDecodeFcn'.
Pass Job and Task Data
The third input argument (after cluster and job) to the submit function is the object with the properties listed in the following table.
You do not set the values of any of these properties. They are automatically set by the toolbox so that you can program your submit function to forward them to the worker nodes.
Property Name | Description |
|---|---|
| Character vector. Used internally to indicate that a file system is used to contain job and task data. |
| Character vector. Derived from the cluster |
| Character vector. Indicates where this job’s data is stored. |
| Cell array. Indicates where each task’s data is stored. Each element of this array is passed to a separate worker. |
| Double. Indicates the number of tasks in the job. You do not need to pass this value to the worker, but you can use it within your submit function. |
With these values passed into your submit function, the function can pass them to the worker nodes by any of several means. However, because the name of the decode function must be passed as an environment variable, the examples that follow pass all the other necessary property values also as environment variables.
The submit function writes the values of these object properties
out to environment variables with the setenv function.
Define Scheduler Command to Run MATLAB Workers
The submit function must define the command necessary for your scheduler to start MATLAB workers. The actual command is specific to your scheduler and network configuration. The commands for some popular schedulers are listed in the following table. This table also indicates whether or not the scheduler automatically passes environment variables with its submission. If not, your command to the scheduler must accommodate these variables.
Scheduler | Scheduler Command | Passes Environment Variables |
|---|---|---|
LSF® |
| Yes, by default. |
PBS |
| Command must specify which variables to pass. |
Sun™ Grid Engine |
| Command must specify which variables to pass. |
Your submit function might also use some of these properties
and others when constructing and invoking your scheduler command. cluster, job,
and props (so named only for this example) refer
to the three arguments to the submit function.
Argument Object | Property |
|---|---|
|
|
|
|
|
|
|
|
Example — Write the Submit Function
The submit function in this example uses environment variables to pass the necessary information to the worker nodes. Each step below indicates the lines of code you add to your submit function.
Create the function declaration. Three objects are automatically passed into the submit function as input arguments: the cluster object, the job object, and the props object.
function independentSubmitFcn(cluster, job, props)
You can use the
AdditionalPropertiesproperty to pass additional information into the submit function, as discussed in MATLAB Client Submit Function.Identify the values you want to send to your environment variables. For convenience, you define local variables for use in this function.
decodeFcn = 'mydecodefunc'; jobLocation = get(props, 'JobLocation'); taskLocations = get(props, 'TaskLocations'); %This is a cell array storageLocation = get(props, 'StorageLocation'); storageConstructor = get(props, 'StorageConstructor');
The name of the decode function that must be available on the MATLAB worker path is
mydecodefunc.Set the environment variables, other than the task locations. All the MATLAB workers use these values when evaluating tasks of the job.
setenv('MDCE_DECODE_FUNCTION', decodeFcn); setenv('MDCE_JOB_LOCATION', jobLocation); setenv('MDCE_STORAGE_LOCATION', storageLocation); setenv('MDCE_STORAGE_CONSTRUCTOR', storageConstructor);Your submit function can use any names you choose for the environment variables, with the exception of
MDCE_DECODE_FUNCTION; the MATLAB worker looks for its decode function identified by this variable. If you use alternative names for the other environment variables, be sure that the corresponding decode function also uses your alternative variable names. You can see the variable names used in the standard decode function by typingedit parallel.cluster.generic.independentDecodeFcn
Set the task-specific variables and scheduler commands. This is where you instruct your scheduler to start MATLAB workers for each task.
for i = 1:props.NumberOfTasks setenv('MDCE_TASK_LOCATION', taskLocations{i}); constructSchedulerCommand; endThe line
constructSchedulerCommandrepresents the code you write to construct and execute your scheduler’s submit command. This command is typically a character vector that combines the scheduler command with necessary flags, arguments, and values derived from the values of your object properties. This command is inside thefor-loop so that your scheduler gets a command to start a MATLAB worker on the cluster for each task.Note
If you are not familiar with your network scheduler, ask your system administrator for help.
MATLAB Worker Decode Function
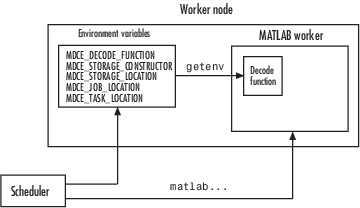
The sole purpose of the MATLAB worker’s decode function is to read certain job and task information into the MATLAB worker session. This information could be stored in disk files on the network, or it could be available as environment variables on the worker node. Because the discussion of the submit function illustrated only the usage of environment variables, so does this discussion of the decode function.
When working with the decode function, you must be aware of the
Name and location of the decode function itself
Names of the environment variables this function must read
Note
Standard decode functions are now included in the product. If
your submit functions make use of the definitions in these decode
functions, you do not have to provide your own decode functions. For
example, to use the standard decode function for independent jobs,
in your submit function set MDCE_DECODE_FUNCTION to 'parallel.cluster.generic.independentDecodeFcn'.
The remainder of this section is useful only if you use names and
settings other than the standards used in the provided decode functions.
Identify File Name and Location
The client’s submit function and the worker’s
decode function work together as a pair. For more information on the
submit function, see MATLAB Client Submit Function. The decode function
on the worker is identified by the submit function as the value of
the environment variable MDCE_DECODE_FUNCTION.
The environment variable must be copied from the client node to the
worker node. Your scheduler might perform this task for you automatically;
if it does not, you must arrange for this copying.
The value of the environment variable MDCE_DECODE_FUNCTION defines
the filename of the decode function, but not its location. The file
cannot be passed as part of the job AdditionalPaths or AttachedFiles property,
because the function runs in the MATLAB worker before that session
has access to the job. Therefore, the file location must be available
to the MATLAB worker as that worker starts.
Note
The decode function must be available on the MATLAB worker’s path.
You can get the decode function on the worker’s path
by either moving the file into a folder on the path (for example, matlabroot/toolbox/localcd in its command
so that it starts the MATLAB worker from within the folder that
contains the decode function.
In practice, the decode function might be identical for all workers on the cluster. In this case, all workers can use the same decode function file if it is accessible on a shared drive.
When a MATLAB worker starts, it automatically runs the
file identified by the MDCE_DECODE_FUNCTION environment
variable. This decode function runs before the
worker does any processing of its task.
Read the Job and Task Information
When the environment variables have been transferred from the
client to the worker nodes (either by the scheduler or some other
means), the decode function of the MATLAB worker can read them
with the getenv function.
With those values from the environment variables, the decode
function must set the appropriate property values of the object that
is its argument. The property values that must be set are the same
as those in the corresponding submit function, except that instead
of the cell array TaskLocations, each worker has
only the individual character vector TaskLocation,
which is one element of the TaskLocations cell
array. Therefore, the properties you must set within the decode function
on its argument object are as follows:
StorageConstructorStorageLocationJobLocationTaskLocation
Example — Write the Decode Function
The decode function must read four environment variables and use their values to set the properties of the object that is the function’s output.
In this example, the decode function’s argument is the
object props.
function props = workerDecodeFunc(props)
% Read the environment variables:
storageConstructor = getenv('MDCE_STORAGE_CONSTRUCTOR');
storageLocation = getenv('MDCE_STORAGE_LOCATION');
jobLocation = getenv('MDCE_JOB_LOCATION');
taskLocation = getenv('MDCE_TASK_LOCATION');
%
% Set props object properties from the local variables:
set(props, 'StorageConstructor', storageConstructor);
set(props, 'StorageLocation', storageLocation);
set(props, 'JobLocation', jobLocation);
set(props, 'TaskLocation', taskLocation);
When the object is returned from the decode function to the MATLAB worker session, its values are used internally for managing job and task data.
Example — Program and Run a Job in the Client
1. Create a Scheduler Object
You use the parcluster function
to create an object representing the cluster in your local MATLAB client
session. Use a profile based on the generic type of cluster
c = parcluster('MyGenericProfile')If your cluster uses a shared file system for workers to access
job and task data, set the JobStorageLocation and HasSharedFilesystem properties
to specify where the job data is stored and that the workers should
access job data directly in a shared file system.
c.JobStorageLocation = '\\share\scratch\jobdata'
c.HasSharedFilesystem = trueNote
All nodes require access to the folder specified in the cluster
object’s JobStorageLocation property.
If JobStorageLocation is not set, the default
location for job data is the current working directory of the MATLAB client
the first time you use parcluster to create an
object for this type of cluster, which might not be accessible to
the worker nodes.
If MATLAB is not on the worker’s system path, set
the ClusterMatlabRoot property to specify where
the workers are to find the MATLAB installation.
c.ClusterMatlabRoot = '\\apps\matlab\'
You can look at all the property settings on the scheduler object.
If no jobs are in the JobStorageLocation folder,
the Jobs property is a 0-by-1 array. All settable
property values on a scheduler object are local to the MATLAB client,
and are lost when you close the client session or when you remove
the object from the client workspace with delete or clear
all.
c
You must set the IntegrationScriptsLocation property
to specify the folder containing the submit functions for this cluster.
c.IntegrationScriptsLocation = '\\scripts\myIntegrationScripts';You can now define the scheduler object, and the user-defined submit and decode functions. Programming and running a job is now similar to doing so with any other type of supported scheduler.
2. Create a Job
You create a job with the createJob function,
which creates a job object in the client session. The job data is
stored in the folder specified by the cluster object's JobStorageLocation property.
j = createJob(c)
This statement creates the job object j in
the client session.
Note
Properties of a particular job or task should be set from only one computer at a time.
This generic scheduler job has somewhat different properties than a job that uses an MJS. For example, this job has no callback functions.
The job’s State property is pending.
This state means the job has not been queued for running yet. This
new job has no tasks, so its Tasks property is
a 0-by-1 array.
The cluster’s Jobs property is now
a 1-by-1 array of job objects, indicating the existence of your job.
c
3. Create Tasks
After you have created your job, you can create tasks for the job. Tasks define the functions to be evaluated by the workers during the running of the job. Often, the tasks of a job are identical except for different arguments or data. In this example, each task generates a 3-by-3 matrix of random numbers.
createTask(j, @rand, 1, {3,3});
createTask(j, @rand, 1, {3,3});
createTask(j, @rand, 1, {3,3});
createTask(j, @rand, 1, {3,3});
createTask(j, @rand, 1, {3,3});The Tasks property of j is
now a 5-by-1 matrix of task objects.
j.Tasks
Alternatively, you can create the five tasks with one call to createTask by providing a cell array
of five cell arrays defining the input arguments to each task.
T = createTask(job1, @rand, 1, {{3,3} {3,3} {3,3} {3,3} {3,3}});In this case, T is a 5-by-1 matrix of task
objects.
4. Submit a Job to the Job Queue
To run your job and have its tasks evaluated, you submit the job to the scheduler’s job queue.
submit(j)
The scheduler distributes the tasks of j to MATLAB workers
for evaluation.
The job runs asynchronously. If you need to wait for it to complete
before you continue in your MATLAB client session, you can use
the wait function.
wait(j)
This function pauses MATLAB until the State property
of j is 'finished' or 'failed'.
5. Retrieve the Job's Results
The results of each task’s evaluation are stored in that
task object’s OutputArguments property
as a cell array. Use fetchOutputs to
retrieve the results from all the tasks in the job.
results = fetchOutputs(j);
Display the results from each task.
results{1:5} 0.9501 0.4860 0.4565
0.2311 0.8913 0.0185
0.6068 0.7621 0.8214
0.4447 0.9218 0.4057
0.6154 0.7382 0.9355
0.7919 0.1763 0.9169
0.4103 0.3529 0.1389
0.8936 0.8132 0.2028
0.0579 0.0099 0.1987
0.6038 0.0153 0.9318
0.2722 0.7468 0.4660
0.1988 0.4451 0.4186
0.8462 0.6721 0.6813
0.5252 0.8381 0.3795
0.2026 0.0196 0.8318Support Scripts
To use the generic scheduler interface, you can install templates and scripts from the following locations:
Each installer provides templates and scripts for the supported
submission modes for shared file system, nonshared file system, or
remote submission. Each submission mode has its own subfolder within
the installation folder. The subfolder contains a file named README that
provides specific instructions on how to use the scripts. To use these
support scripts with your cluster object, set the IntegrationScriptsLocation property
to the location of this subfolder.
For more information on programming jobs for generic schedulers, see:
For each scheduler type, the folder (or configuration subfolder) contains wrappers, submit functions, and other job management scripts for independent and communicating jobs. For example, you can install the following files for use with a PBS scheduler:
| Filename | Description |
|---|---|
independentSubmitFcn.m | Submit function for a independent job |
communicatingSubmitFcn.m | Submit function for a communicating job |
independentJobWrapper.sh | Script that is submitted to PBS to start workers that evaluate the tasks of an independent job |
communicatingJobWrapper.sh | Script that is submitted to PBS to start workers that evaluate the tasks of a communicating job |
deleteJobFcn.m | Script to delete a job from the scheduler |
extractJobId.m | Script to get the job’s ID from the scheduler |
getJobStateFcn.m | Script to get the job's state from the scheduler |
getSubmitString.m | Script to get the submission character vector for the scheduler |
postConstructFcn.m | Script that is run following cluster object creation |
These files are all programmed to use the standard decode functions provided with the product, so they do not have specialized decode functions.
The folders for other scheduler types contain similar files.
As more files or solutions for more schedulers might become
available at any time, visit the product page at http://www.mathworks.com/products/distriben/.
This Web page provides links to updates, supported schedulers, requirements,
and contact information in case you have any questions.
Manage Jobs with Generic Scheduler
While you can use the cancel and delete methods on jobs that use the
generic scheduler interface, by default these methods access or affect
only the job data where it is stored on disk. To cancel or delete
a job or task that is currently running or queued, you must provide
instructions to the scheduler directing it what to do and when to
do it. To accomplish this, the toolbox provides a means of saving
data associated with each job or task from the scheduler, and a set
of properties to define instructions for the scheduler upon each cancel
or destroy request.
Save Job Scheduler Data
The first requirement for job management is to identify the
job from the cluster’s perspective. When you submit a job to
the cluster, the command to do the submission in your submit function
can return from the scheduler some data about the job. This data typically
includes a job ID. By storing that job ID with the job, you can later
refer to the job by this ID when you send management commands to the
scheduler. Similarly, you can store information, such as an ID, for
each task. The toolbox function that stores this cluster data is setJobClusterData.
If your scheduler accommodates submission of entire jobs (collection of tasks) in a single command, you might get back data for the whole job and/or for each task. Part of your submit function might be structured like this:
for ii = 1:props.NumberOfTasks
define scheduler command per task
end
submit job to scheduler
data_array = parse data returned from scheduler %possibly NumberOfTasks-by-2 matrix
setJobClusterData(cluster, job, data_array)
If your scheduler accepts only submissions of individual tasks, you might get return data pertaining to only each individual tasks. In this case, your submit function might have code structured like this:
for ii = 1:props.NumberOfTasks
submit task to scheduler
%Per-task settings:
data_array(1,ii) = ... parse character vector returned from scheduler
data_array(2,ii) = ... save ID returned from scheduler
etc
end
setJobClusterData(scheduler, job, data_array)Define Scheduler Commands in User Functions
You now have the scheduler data (such as the scheduler’s ID for the job or task) stored on disk along with the rest of the job data. You can then write code to control what the scheduler should do when that particular job or task is canceled or destroyed.
To do so, create the following functions:
cancelJobFcn.mdeleteJobFcn.mcancelTaskFcn.mdeleteTaskFcn.m
Your cancelJobFcn.m function defines what
you want to communicate to your scheduler in the event that you use
the cancel function on your job from the MATLAB
client. The toolbox takes care of the job state and any data management
with the job data on disk. Therefore your cancelJobFcn.m function
needs to deal only with the part of the job currently running or queued
with the scheduler. The toolbox function that retrieves scheduler
data from the job is getJobClusterData.
Your cancel function must have the following signature:
function cancelJobFcn(sched, job)
array_data = getJobClusterData(clust, job)
job_id = array_data(...) % Extract the ID from the data, depending on how
% it was stored in the submit function above.
command to scheduler canceling job job_idIn a similar way, you can define what you want your scheduler to do when deleting a job, or when canceling and deleting tasks.
Delete or Cancel a Running Job
To use your functions with your cluster, you must locate the
functions in the folder identified by the IntegrationScriptsLocation property
of your cluster object.
Continue with job creation and submission as usual.
j1 = createJob(c); for ii = 1:n t(ii) = createTask(j1,...) end submit(j1)
While the job is running or queued, you can cancel or delete the job or a task.
This command cancels the task and moves it to the finished state.
The cancelJobFcn function is executed, and sends
the appropriate commands to the scheduler:
cancel(t(4))
This command deletes job data for j1. The deleteJobFcn function
is executed, and sends the appropriate commands to the scheduler:
delete(j1)
Get State Information About a Job or Task
When using a third-party scheduler, it is possible that the
scheduler itself can have more up-to-date information about your jobs
than what is available to the toolbox from the job storage location.
To retrieve that information from the scheduler, you can write a function
called getJobStateFcn.m. You must place this function
in the folder identified by the IntegrationScriptsLocation property
of your cluster object. The function must have the following signature:
function getJobStateFcn (cluster, job, state)Suppose that you use a toolbox function such as wait, etc., that accesses the state
of a job on the generic scheduler. After retrieving the state from
storage, the toolbox runs the getJobStateFcn.m function
located in IntegrationScriptsLocation. The result
is returned in place of the stored state. The function you write for
this purpose must return a valid value for the State of
a job object.
When using the generic scheduler interface in a nonshared file
system environment, the remote file system might be slow in propagating
large data files back to your local data location. Therefore, a job’s State property
might indicate that the job is finished some time before all its data
is available to you.
Summary
The following list summarizes the sequence of events that occur when running a job that uses the generic scheduler interface:
Provide a submit function and a decode function. Be sure the decode function is on all the MATLAB workers’ search paths.
The following steps occur in the MATLAB client session:
Define the
IntegrationScriptsLocationproperty of your scheduler object to the folder containing your submit function.Send your job to the scheduler.
submit(job)
The client session runs the submit function.
The submit function sets environment variables with values derived from its arguments.
The submit function makes calls to the scheduler — generally, a call for each task (with environment variables identified explicitly, if necessary).
The following step occurs in your network:
For each task, the scheduler starts a MATLAB worker session on a cluster node.
The following steps occur in each MATLAB worker session:
The MATLAB worker automatically runs the decode function, finding it on the path.
The decode function reads the pertinent environment variables.
The decode function sets the properties of its argument object with values from the environment variables.
The MATLAB worker uses these object property values in processing its task without your further intervention.